目录
当 AI 学会刷 Instagram:instagram-mcp 项目深度解析

在大模型工具调用(Tool Use)能力日趋成熟的今天,MCP(Model Context Protocol)正在成为连接 AI 与外部世界的标准协议。本文将深入解析一个有趣的开源项目 instagram-mcp——它通过 MCP 协议,让 AI 智能体能够直接搜索 Instagram 用户、浏览帖子和获取详细内容,打通了大语言模型与社交媒体数据之间的桥梁。
项目地址:github.com/xishandong/instagram-mcp
一、项目背景:为什么需要 Instagram MCP?
MCP(Model Context Protocol)是 Anthropic 提出的一套开放协议,旨在标准化 AI 模型与外部工具、数据源之间的交互方式。通过 MCP,AI Agent 可以像调用函数一样使用外部服务——而 instagram-mcp 就是这一理念在社交媒体领域的落地实践。
Instagram 作为全球最大的图片社交平台之一,拥有海量的公开用户数据和内容。然而,Instagram 官方 API 的访问限制非常严格,普通开发者几乎无法获得数据读取权限。instagram-mcp 另辟蹊径,通过第三方 Instagram 数据镜像站 imginn.com 来获取公开数据,并将这些数据以结构化的方式暴露给 AI 智能体。
这意味着,接入这个 MCP Server 之后,你可以直接对 AI 说:"帮我搜索一下某某用户的 Instagram,看看他最近发了什么"——而 AI 会自动调用相应的工具,完成从搜索、获取资料到解析帖子详情的全流程。
二、整体架构
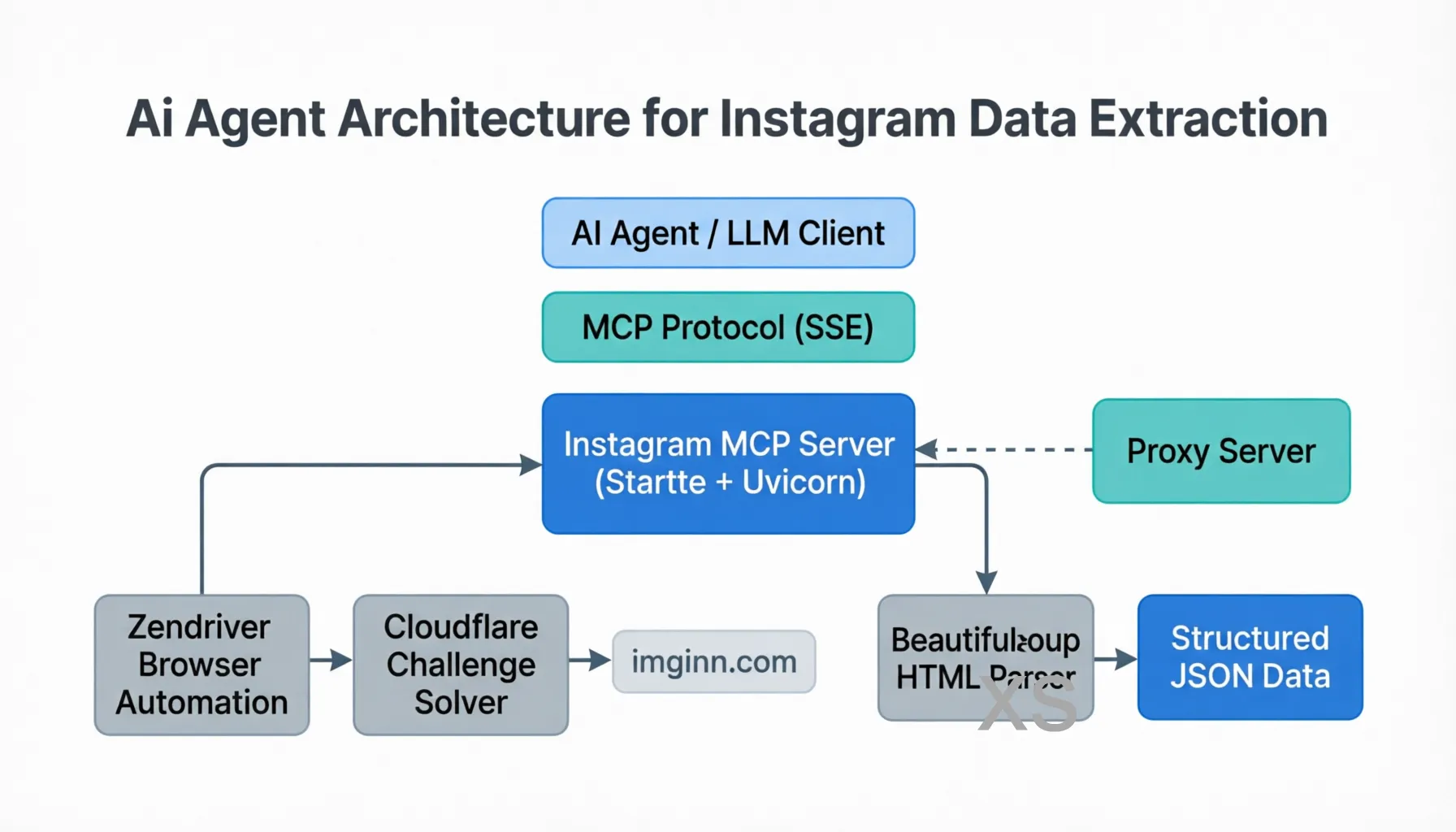 instagram-mcp 的架构可以分为四个核心层次:
instagram-mcp 的架构可以分为四个核心层次:
协议层——基于 MCP SDK 构建的标准化工具接口,通过 SSE(Server-Sent Events)协议与 AI 客户端通信。底层 Web 服务使用 Starlette 框架配合 Uvicorn 异步服务器,提供 /sse 端点供 AI Agent 连接,/messages/ 端点接收工具调用请求,以及 /health 健康检查端点。
浏览器引擎层——使用 zendriver(一个基于 Chrome DevTools Protocol 的 Python 浏览器自动化库)驱动真实的 Chrome 浏览器实例。之所以选择真实浏览器而不是简单的 HTTP 请求库,核心原因在于 imginn.com 部署了 Cloudflare 反爬保护,需要通过真实浏览器环境来绕过验证。
数据解析层——使用 BeautifulSoup4 对获取到的 HTML 页面进行结构化解析,从中提取用户信息、帖子内容、图片/视频链接、点赞数、评论数等字段,将非结构化的网页数据转化为干净的 JSON 格式返回给 AI。
网络代理层——由于访问 Instagram 相关站点通常需要代理,项目内置了完善的代理支持,包括 HTTP/SOCKS5 代理、带认证的代理,以及 Docker 环境下的自动地址转换。
项目文件结构
instagram-mcp/ ├── instagram_mcp/ │ ├── __init__.py # 包初始化 │ ├── server.py # MCP 服务器主入口,路由与工具调度 │ ├── client.py # Instagram 客户端,浏览器驱动与数据获取 │ ├── tools.py # MCP 工具定义(JSON Schema) │ ├── post_parser.py # 帖子 HTML 解析器 │ └── utils.py # 工具函数:代理类、搜索结果解析、JSON 提取 ├── requirements.txt └── README.md
三、核心技术解析
3.1 MCP Server 实现:从协议到服务
MCP Server 的核心在 server.py 中实现。项目使用 MCP SDK 的 Server 类创建服务实例,并通过 @server.list_tools() 和 @server.call_tool() 两个装饰器注册工具列表和调用处理逻辑。
pythondef create_server():
server = Server(name="instagram-mcp", version="1.0.0")
client = InstagramClient(proxy_url=init_proxy, headless=init_headless)
@server.list_tools()
async def list_tools():
tools = get_instagram_tools()
tools.append(configure_tool)
tools.append(close_browser_tool)
return tools
@server.call_tool()
async def call_tool(name: str, arguments: dict):
if name == "search_users":
result = await client.search_user(arguments.get("query"))
return [TextContent(type="text", text=json.dumps(result))]
# ... 其他工具处理
项目注册了 6 个 MCP 工具,每个工具都有明确的 JSON Schema 定义输入参数。configure 和 close_browser 是服务管理类工具,其余四个(search_users、get_user_profile、get_user_posts、get_post_detail)是核心数据获取工具。
值得注意的是配置热更新机制:每次工具调用时,服务器都会重新读取配置文件,如果发现代理或浏览器配置发生了变化,会自动关闭旧的浏览器实例并用新配置重新初始化,无需重启服务。
pythonif proxy != init_proxy or headless != init_headless:
logger.warning("用户配置了代理,重新初始化浏览器")
await client.close()
client.headless = headless
client.proxy_url = proxy
通信层面,MCP Server 使用 SSE(Server-Sent Events)作为传输协议。Starlette 应用挂载了三个路由:/sse 建立 SSE 长连接、/messages/ 接收 POST 消息、/health 返回健康状态。同时配置了全域 CORS 中间件,允许任何来源的 AI 客户端接入。
3.2 浏览器自动化与 Cloudflare 绕过
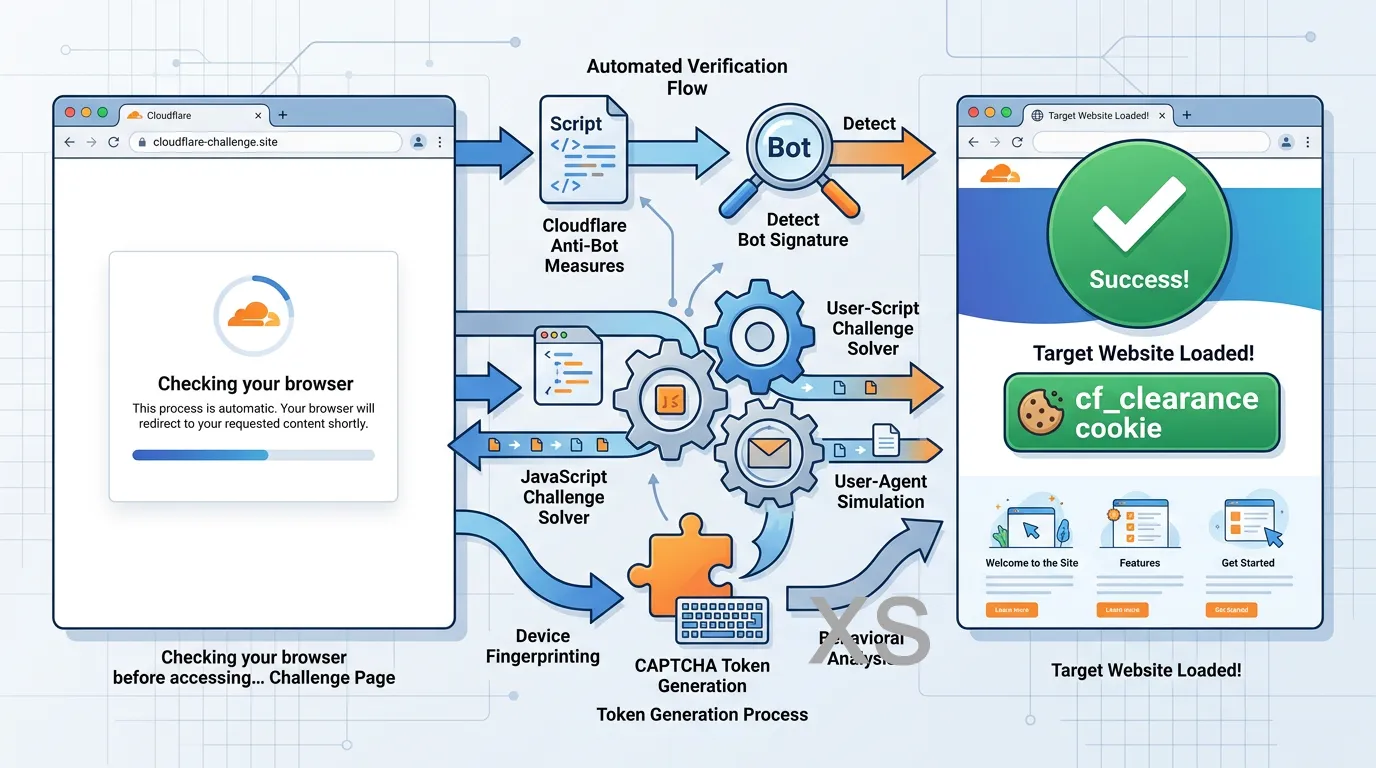
这是整个项目最精妙的部分。client.py 中的 InstagramClient 类封装了一套完整的浏览器自动化方案,核心使用 zendriver 库——一个基于 CDP(Chrome DevTools Protocol)的异步浏览器控制库。
为什么不用 requests? imginn.com 使用了 Cloudflare 的反机器人保护。普通 HTTP 请求会被拦截在 Cloudflare 的 JavaScript Challenge 页面上。只有真实浏览器能执行 Cloudflare 的验证脚本并获取 cf_clearance cookie,从而正常访问目标页面。
Cloudflare 挑战的自动处理分为三步:
第一步是挑战检测。detect_challenge() 方法解析页面 HTML,查找 Cloudflare 挑战标识字符串来判断当前遇到的挑战类型——支持 non-interactive(JavaScript 自动验证)、managed(可能需要点击)和 interactive(需要交互验证码)三种类型。
pythonclass ChallengePlatform(Enum):
JAVASCRIPT = "non-interactive"
MANAGED = "managed"
INTERACTIVE = "interactive"
async def detect_challenge(self) -> Optional[ChallengePlatform]:
html = await self.driver.main_tab.get_content()
for platform in ChallengePlatform:
if f"cType: '{platform.value}'" in html:
return platform
return None
第二步是自动解题。solve_challenge() 方法在一个循环中反复检查是否已经获取到 cf_clearance cookie。如果未获取到且检测到验证挑战仍在进行,它会尝试定位 Cloudflare 的验证 Widget(位于 Shadow DOM 中),然后在按钮区域内以随机偏移量模拟鼠标点击,以绕过机器人检测。
pythonawait self.driver.main_tab.mouse_click(
position.x + random.randint(14, 31),
position.y + random.randint(24, 42)
)
这里使用随机偏移而非精确坐标点击,是为了模拟人类操作的不确定性,降低被 Cloudflare 行为分析检测到的概率。
第三步是Cookie 验证。通过 CDP 协议获取浏览器的所有 Cookie,检查其中是否包含名为 cf_clearance 的 Cookie,以此判断挑战是否已成功解决。
此外,项目还做了一个巧妙的 Monkey Patch:由于新版 Chrome 移除了 Cookie 中的 sameParty 字段,而 zendriver 的序列化逻辑未及时跟进,会导致 KeyError。项目在入口处 patch 了 Cookie.from_json 方法,为缺失的字段设置默认值:
python@classmethod
def _patched_cookie_from_json(cls, json):
json.setdefault("sameParty", False)
return _original_cookie_from_json(cls, json)
3.3 代理系统与 Docker 适配
代理支持是项目可用性的关键。utils.py 中定义了一个简洁的 Proxy 数据类,能够从标准 URL 格式解析出 scheme、host、port、username 和 password 各字段。
对于需要认证的代理服务器,项目使用了 CDP 的 Fetch 域来拦截代理认证请求。当浏览器遇到代理的 407 响应时,_on_auth_required 回调会自动填入用户名和密码:
pythonasync def _on_auth_required(self, event: AuthRequired) -> None:
if event.auth_challenge.source == "Proxy":
await self.driver.main_tab.send(
cdp.fetch.continue_with_auth(
event.request_id,
AuthChallengeResponse(
response="ProvideCredentials",
username=self._proxy.username,
password=self._proxy.password,
),
)
)
另一个亮点是 Docker 环境自适应。当项目运行在 Docker 容器内时,用户配置的 127.0.0.1 或 localhost 代理地址实际指向的是容器自身而非宿主机。项目通过检测 /.dockerenv 文件和 /proc/1/cgroup 来判断是否在容器内运行,如果是,则自动将本地地址替换为 host.docker.internal,确保代理连接正确指向宿主机。
3.4 HTML 解析与数据提取
post_parser.py 是数据结构化的核心。它针对 imginn.com 的 HTML 结构精心编写,能够从帖子页面中提取出丰富的结构化数据。
解析器处理了两种帖子类型:单媒体帖子(单张图片或单个视频)和轮播帖子(多图/多视频混合)。对于轮播帖子,解析器会遍历 Swiper 滑动容器中的每个 slide,分别识别其中是图片还是视频,并收集对应的媒体 URL。
pythonswiper_slides = swiper_container.find_all('div', class_='swiper-slide')
for slide in swiper_slides:
media_wrap = slide.find('div', class_='media-wrap')
video_tag = media_wrap.find('video')
if video_tag:
# 处理视频
videos.append(video_src)
else:
# 处理图片,优先取 data-src(懒加载)
src = img_tag.get('data-src') or img_tag.get('src')
最终,每个帖子被解析为包含以下字段的字典:帖子 URL、图片列表、视频列表、点赞数、评论数、用户信息、被标记用户、帖子文案、发布时间,以及帖子类型(image / video / carousel / unknown)。
utils.py 中的 parse_imginn_search_results() 则负责解析搜索结果页面,从每个用户卡片中提取头像、用户名、全名、个人主页链接,以及是否已认证(蓝色徽章)等信息。
四、工作流程
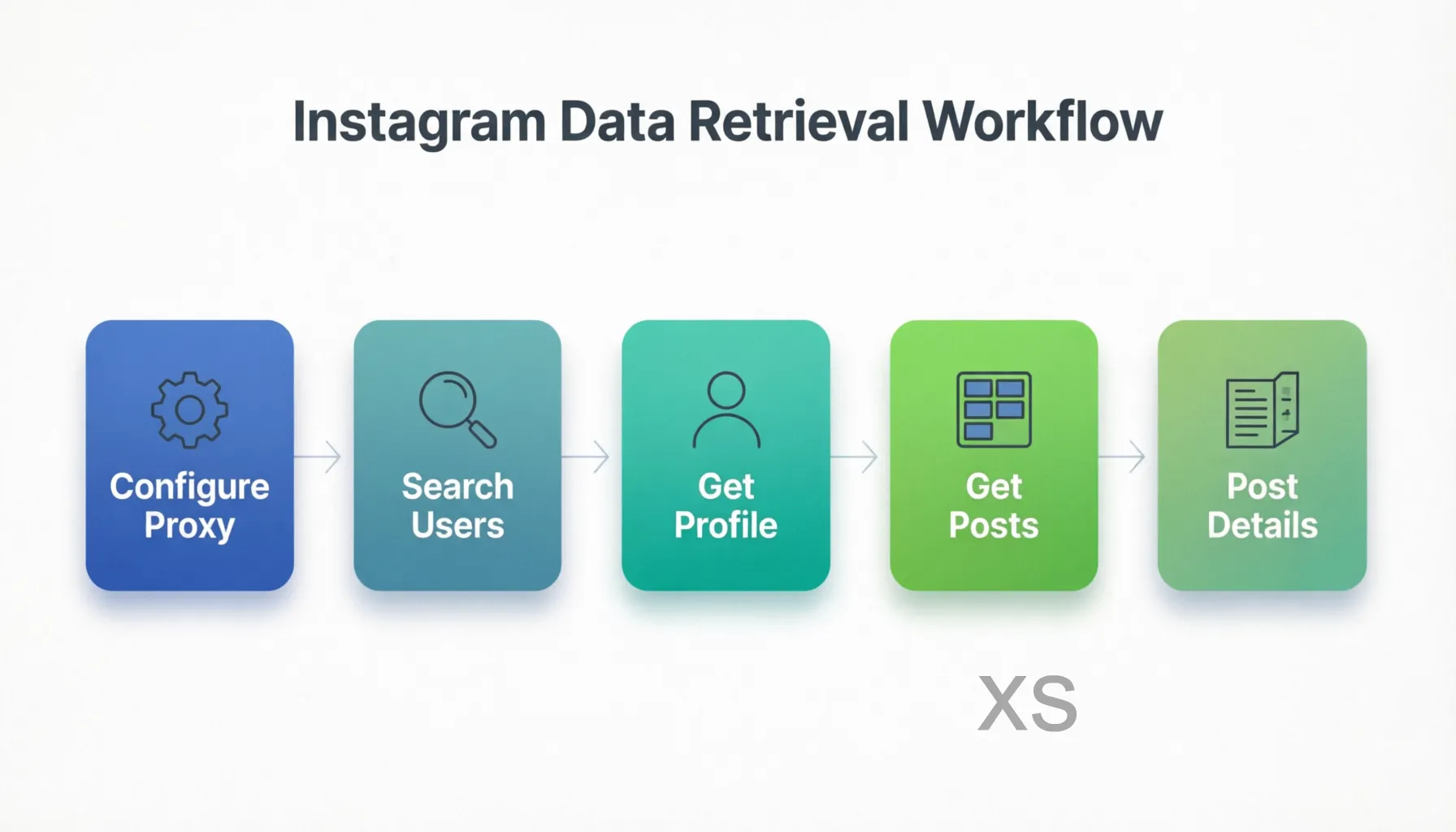
instagram-mcp 的典型使用流程如下:
第一步:配置代理。 这是使用前的必要步骤。AI Agent 调用 configure 工具传入代理地址和浏览器模式偏好,配置被写入 ~/.instagram-mcp/config.json 持久化保存。
第二步:搜索用户。 调用 search_users 工具,传入查询关键词。服务器通过浏览器访问 imginn.com 的搜索页面,解析返回的用户列表,每条结果包含用户名、全名、头像和认证状态。
第三步:获取用户资料。 调用 get_user_profile 工具,传入精确的用户名。服务器访问 imginn.com 的 API 接口获取用户详细信息(包含用户 ID,这是后续获取帖子的关键参数)。
第四步:获取帖子列表。 调用 get_user_posts 工具,传入用户 ID。服务器返回帖子列表和分页游标(cursor),AI 可以通过传入 cursor 实现翻页,逐步获取更多帖子。
第五步:获取帖子详情。 对感兴趣的帖子调用 get_post_detail,传入帖子的 shortcode(Instagram URL 中 /p/ 后面的编码)。服务器返回帖子的完整信息:图片/视频 URL、文案内容、互动数据和标记用户等。
在整个流程中,浏览器实例采用懒加载策略——只在首次需要访问网页时才启动 Chrome,避免了服务启动时的资源浪费。使用完毕后,可以调用 close_browser 手动释放浏览器资源,服务器关闭时也会自动清理。
五、技术亮点总结
1. 巧妙的反反爬策略。 真实浏览器 + 随机化点击 + Cookie 管理的三层组合拳,有效应对了 Cloudflare 的层层防护。
2. 配置热更新。 每次工具调用前检查配置变更,自动重建浏览器实例,避免了频繁重启服务的麻烦。
3. Docker 环境感知。 自动检测容器环境并转换代理地址,这个细节体现了对实际部署场景的深入考量。
4. 浏览器懒加载。 不在服务启动时就启动浏览器,而是在首次需要时才初始化,既节省资源又加快了服务启动速度。
5. 完善的代理认证。 通过 CDP Fetch 域拦截 407 响应并自动填入凭证,支持需要用户名密码的企业级代理。
6. 兼容性 Patch。 对 zendriver 库的 Cookie 序列化问题做了 Monkey Patch,体现了在实际工程中处理上下游兼容性问题的务实态度。
六、写在最后
instagram-mcp 虽然代码量不大(核心代码不到 800 行),但麻雀虽小五脏俱全。它涵盖了 MCP Server 开发、浏览器自动化、反爬绕过、HTML 解析、代理管理等多个技术领域,是一个非常好的 MCP Server 开发学习案例。
对于想要开发自己的 MCP Server 的开发者来说,这个项目展示了几个关键的实践模式:如何定义清晰的工具 Schema、如何处理有状态的外部资源(浏览器实例)、如何实现配置的动态更新,以及如何在 SSE 传输层上构建可靠的 MCP 服务。
如果你对 MCP 生态和 AI Agent 工具开发感兴趣,不妨 clone 这个项目动手试试,相信会有不少收获。


本文作者:回锅炒辣椒
本文链接:
版权声明:本博客所有文章除特别声明外,均采用 BY-NC-SA 许可协议。转载请注明出处!